Apache Spark: Overview
Many different tools are used in working with Big Data. Even for the same tasks, there are several technologies, each of which has its own characteristics and disadvantages. It can be difficult to sort out all this variety and choose something.
To help with this, we will introduce one of the tools - Apache Spark . You will learn what it is, how it is used when working with big data, and how it can help. We will also compare it with another similar technology - Hadoop MapReduce .
What is Apache Spark
Apache Spark is a platform used by Big Data for cluster computing and large-scale data processing. Spark processes data in RAM and rarely accesses disk, so it is very fast.
Apache Spark is fully compatible with the Hadoop ecosystem and easily integrates into existing solutions. It does not have its own datastore and can work with various sources: HDFS, Hive, S3, HBase, Cassandra and others. Supports several programming languages: Scala, Python, Java, R, SQL.
Spark is used for data processing such as filtering, sorting, cleaning, validating, and so on. Its place in the process of working with big data is shown in the diagram below:
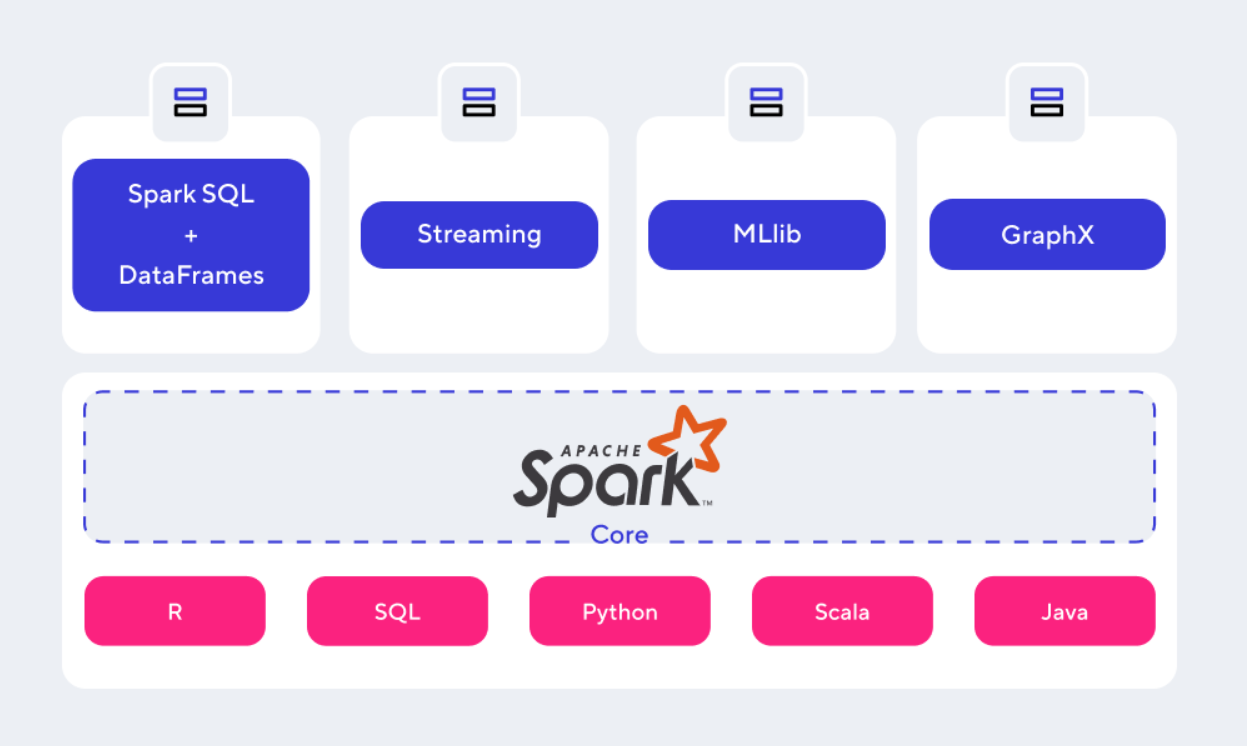
Spark consists of several components.
Apache Spark Core
It is the underlying data engine that underpins the entire platform. The kernel interacts with storage systems, manages memory, schedules and balances the load across the cluster. It is also responsible for maintaining API programming languages.
Spark SQL
This module serves to simplify the work with structured data and allows you to execute queries in the SQL language. Its main task is that data engineers do not think about the distributed nature of data storage, but focus on their use cases.
Streaming
Provides scalable, high-performance and resilient real-time streaming processing. Kafka, Flume, Kinesis and other systems can act as data sources for Spark.
MLlib
It is a scalable low level machine learning library. The library implements various machine learning algorithms such as clustering, regression, classification, and collaborative filtering.
GraphX
Serves for manipulating graphs and their parallel processing. GraphX can measure graph connectivity, degree distribution, average path length, and other metrics. It can also connect graphs and transform them quickly. In addition to built-in graph operations, GraphX also has a library that implements the PageRank algorithm.
Comparison of Apache Spark and Apache MapReduce
Previously, MapReduce was generally used to process big data. It is the Hadoop component that pioneered data processing in Big Data. But he has two global problems.
- Poor performance. MapReduce calculates in two steps. First, it divides the data into pieces and transfers it to the cluster nodes for processing. Then each node processes the data and sends the result to the main node, where the final computation result is formed. MapReduce constantly accesses the disk, where it stores all intermediate and final results of calculations. Therefore, it runs with latencies that prevent MapReduce from being used for processing streaming data and machine learning tasks.
- High complexity. Writing a good MapReduce solution requires a high level of expertise. Even an experienced technician can easily make a mistake or write an ineffective algorithm.
But in 2014, another tool began to gain popularity - Spark, and now it has practically supplanted MapReduce. Apache Spark was designed to address the shortcomings of MapReduce while maintaining its benefits. This is how it solves the MapReduce problems:
-
Spark processes data in memory and hardly ever accesses disk. If the amount of data to be processed is greater than the amount of RAM, Spark flushes some of the data to disk. At the same time, many optimizers are built into it, which can reduce the number of disk accesses. Therefore, Spark is tens, sometimes hundreds of times faster than MapReduce.
-
Spark has APIs for different programming languages, so writing code is much easier and the code itself is more compact. Typically, developers write fairly high-level instructions in Spark, and Spark decides how to execute them optimally. Often he can do it better than a human.
-
For example, a Junior Data-engineer can write code in Spark that will run faster than the code written by a Senior Data-engineer in MapReduce. Also, Spark is less likely to make a serious mistake, and if it does, it is easier to fix it.
To summarize the comparison briefly, we can say that Hadoop MapReduce is an aging technology, and Apache Spark has practically become the standard in the field of big data.
How clouds can power Apache Spark
For data processing in Big Data, horizontal scalability is very important. The more nodes in the cluster, the faster the data is processed. And Spark is no exception. It is difficult and unprofitable to build clusters for data processing on your own equipment. It is difficult to guess in advance how many servers are needed and what capacity they should be. If you use too many servers, they will be idle. If too little, then data processing will take a long time. Therefore, it is worth paying attention to cloud technologies.
Cloud platforms can provide a huge amount of resources on demand. If you have a small load, connect several small nodes. When the load increases, you can quickly add new nodes to the cluster. This will allow you to use resources more efficiently.
Conclusion
- Apache Spark is a framework for processing data in Big Data. It works in RAM and rarely accesses the disk, so it processes data very quickly.
- Previously, the de facto standard for processing data was Hadoop MapReduce. But it has two key problems: low productivity and high development complexity.
- Spark is now practically the standard. It was created to eliminate the disadvantages of MapReduce and to preserve its advantages.
- Apache Spark and other technologies for working with big data are actively used in the cloud, because they allow you to get all the benefits of cloud services.