Creating My Own Dataset By Web Scraping Flipkart.com using Python and Beautiful Soup Library
Well, I wanted to buy a new pair of headphones since a long time and during the same period, I was learning web scraping through some videos, revising SQL for interviews etc. A thought came to my mind, why don’t we just create something that combines hands-on practical experience for the mentioned scenerio?
Let us create our own headphones dataset by scraping some popular website, store it in either Excel or DBMS software such as MySQL, PostgreSQL etc. Run some queries to find and buy the headphone of our choice.
Let us visit flipkart.com one of the giant Indian e-commerce company
Let us search with keyword headphones
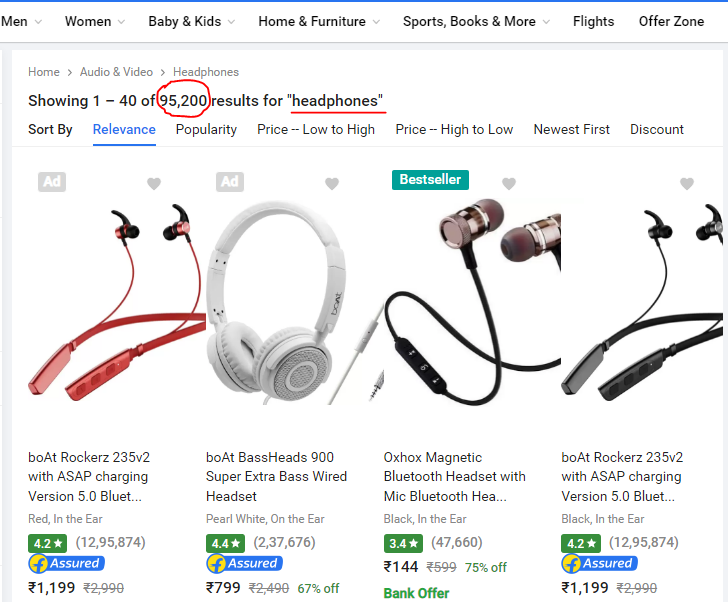
The search (dated: 22-Dec-21) returned 95,200 results which are accessible over 2380 pages!. (Note: The search results are dynamic and may change over time.)
headphone attributes selected to be stored in the database are:
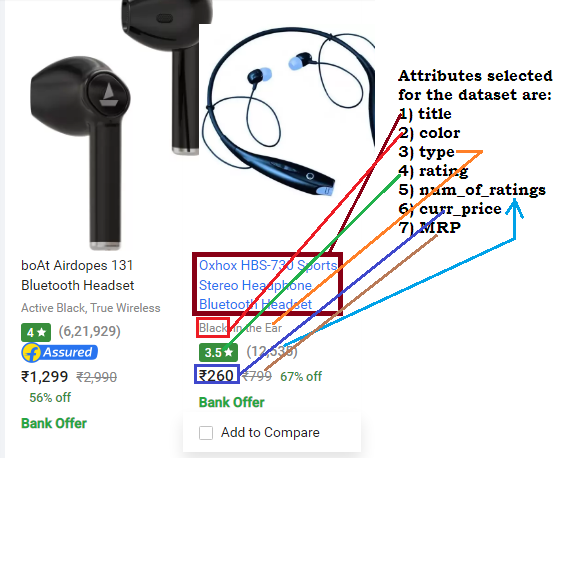
-
title of the headphone product (
title) -
color of the headphone product (
color) -
type of the headphone product (
type) -
average rating of the product (
rating) -
number of ratings available (
num_of_ratings) -
selling price of the headphone at the time of scraping (
curr_price) -
Maximum Retail Price (
MRP)
Let us create our python virtual environment
conda create --name fk_headphones python=3.8
Let us install the required Python libraries
-
requestslibrary -
bs4(beautiful soup) library -
sqlalchemyfor database related functions -
pandasfor handling the tabular data -
jupyter notebook(Optional)
One can use conda list to verify the installation of the above packages
Next steps:
How to extract the title of the first search result?
press Ctrl+Shift+I to open the Developer Tools to inspect the webpage elements. For title we get following information
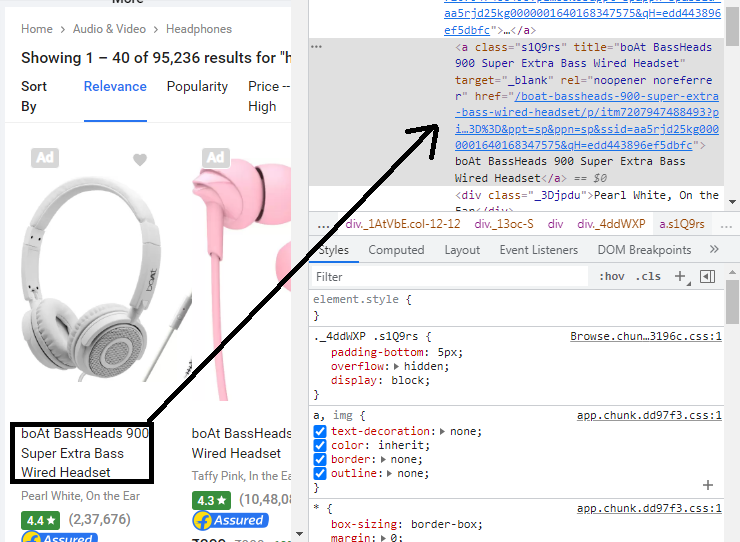
One can see the tag name is a and the class name is s1Q9rs. Let us get all those elements in one variable a_tags. It is expected that the length of this variable should be 40 as there are 40 search results per page.
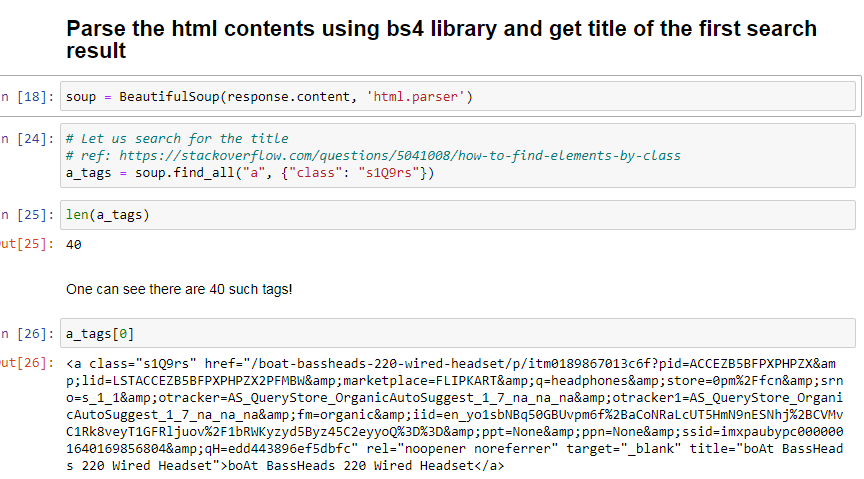
The first element of the a_tags variable shows expected output where the title is embedded which can be extracted as:
a_tags[0].get_text()
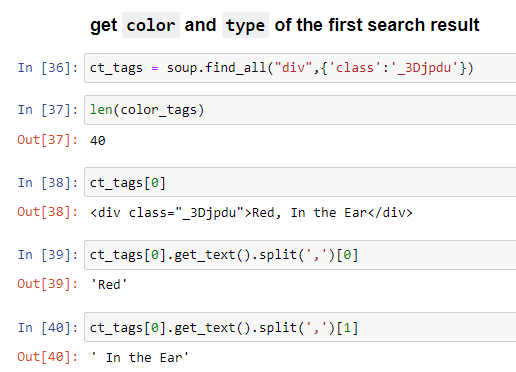
How to extract the color and type of the first search result?
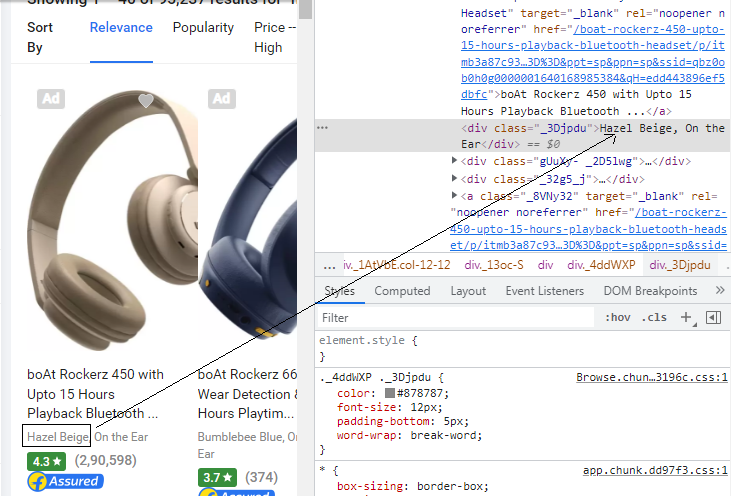
One can see that the tag name is div and class name is _3Djpdu
The color and type of the first result can be extracted as:
How to extract the average rating of the first search result?

The tag name is div and class name is _3LWZIK and the average rating can be obtained as:
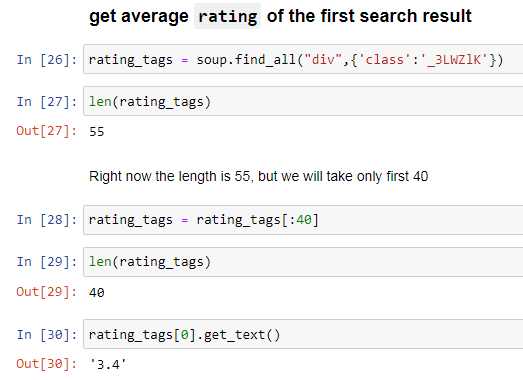
Note: Expected answer above was 4.3 but got 3.4 because the search page results gets updated after few minutes. Hence the product at the first location got changed. But since we are going to run the final program once, we won’t have any issues with the correctness. Updated first search result is as follows:

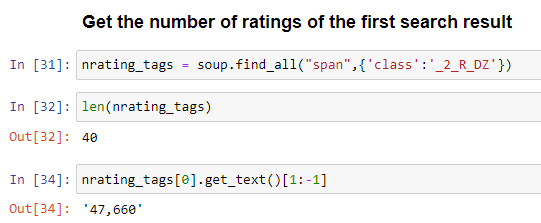
How to extract the num_of_ratings of the first search result?
By inspection, one can see that tag name is span and class name is _2_R_DZ
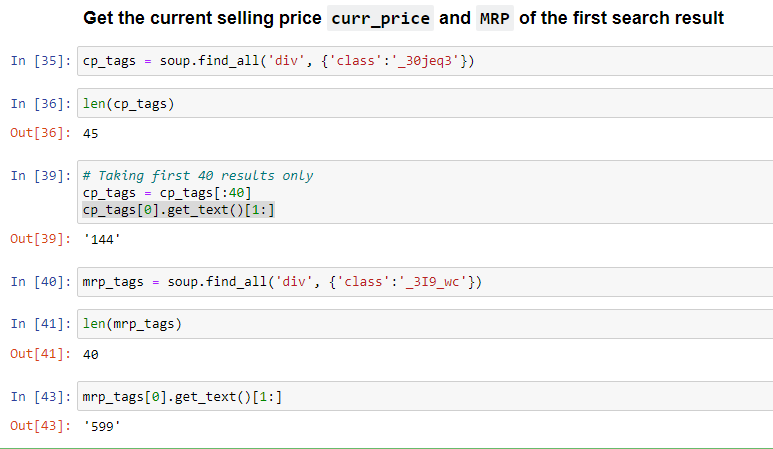
How to extract the curr_price and MRP of the first search result?
For both the tag name is div and class values are:
curr_price: _30jeq3
MRP: _3I9_wc
Scraping the multiple Pages to create our dataset.
For the time being, we will scrape first 55 pages to create our dataset having above mentioned 7 attributes.
We will create 7 empty lists to store the attributes extracted from these pages then we create our dataframe using pandas library.
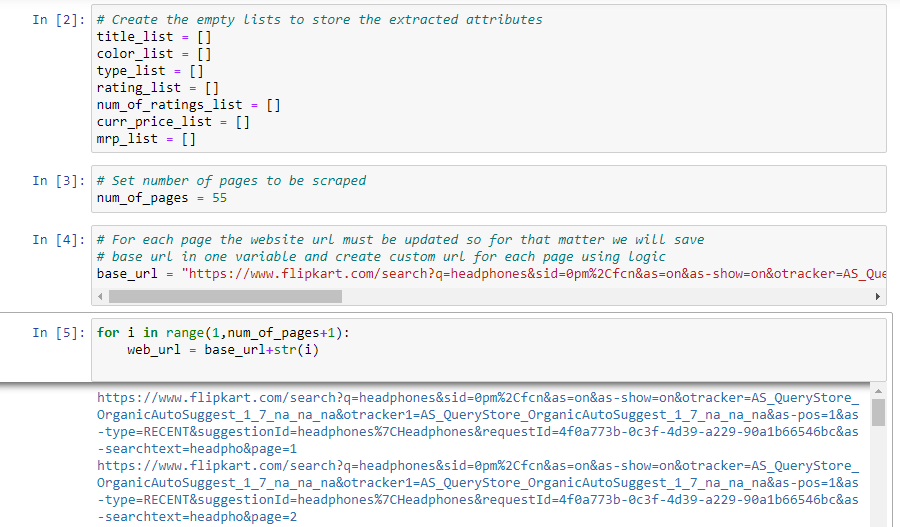
One can check the above logic works fine to create the correct web urls for each page.
Then using the steps described above to extract attribute values, we add more Python statements to obtain themfor each of the 40 items per page. Using the attribute values stored in respective lists, finally a pandas dataframe is created which is then written into both excel and sql format to analyze them using Microsoft Excel and PostgreSQL applications, respectively.
The complete code can be accessed using this GitHub Link.
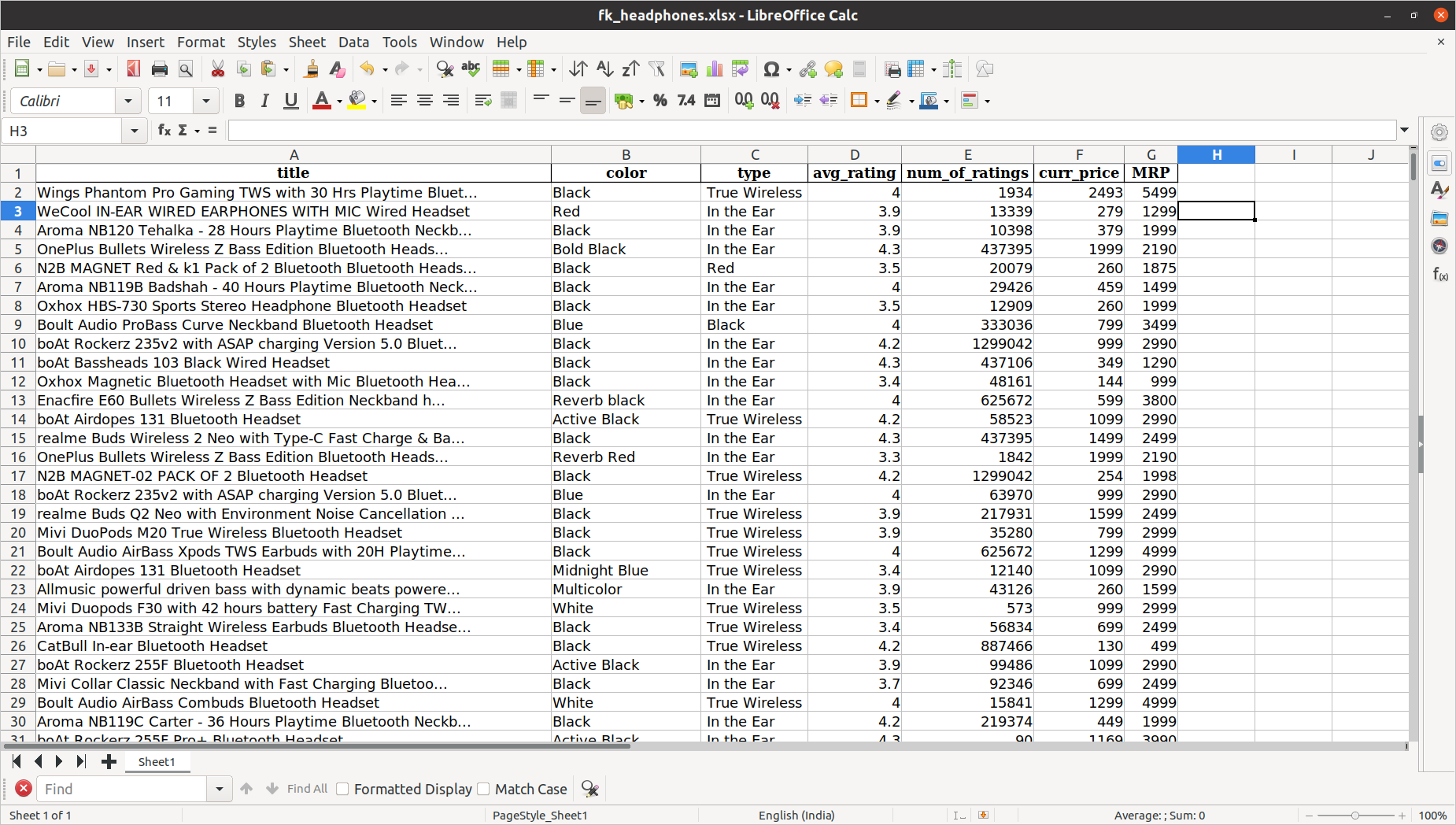
Created Dataset Opened in Excel Aplication
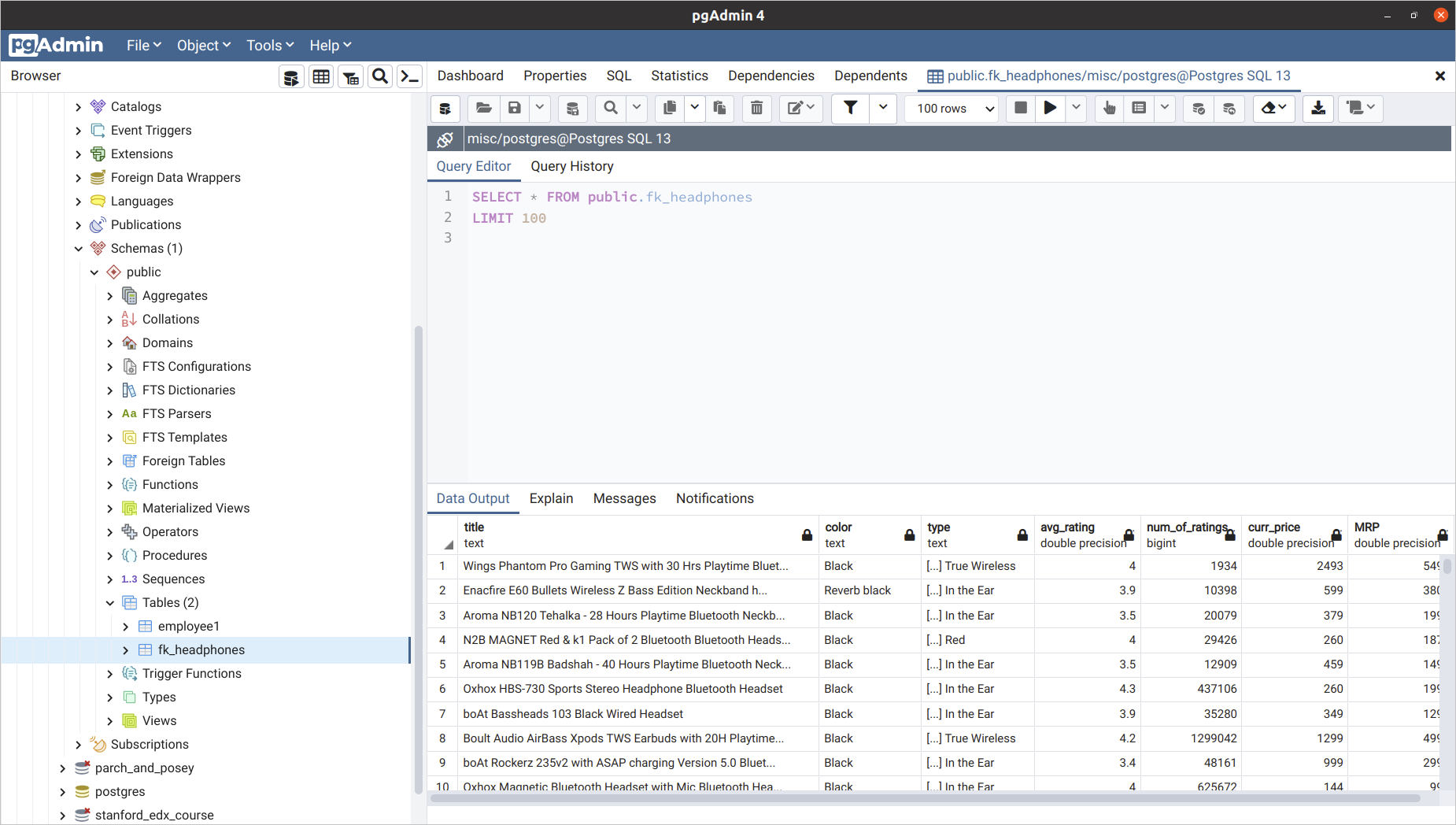
Created Dataset Opened in PostgreSQL Aplication (pgAdmin4)